
ChatGPT is a variant of the GPT (Generative Pre-trained Transformer) model, which is a type of language model developed by OpenAI. The architecture of the model is based on the transformer architecture, which was introduced in the paper “Attention Is All You Need” by Google researchers in 2017.

The model is trained on a large corpus of text data and uses a deep neural network with a transformer architecture to generate human-like text. It has a multi-layer transformer encoder, which consists of multiple layers of self-attention and feed-forward neural networks. The self-attention mechanism allows the model to weigh the importance of each word in the input text when generating the output.
The model also has a decoder, which generates the output text one word at a time. The decoder uses the information from the encoder to generate the output, and it also has an attention mechanism that allows it to focus on specific parts of the input when generating the output.
Additionally, ChatGPT is fine-tuned on conversational data, to make it more proficient in generating responses in a conversational context.
Overall, the ChatGPT architecture is designed to generate highly coherent and contextually appropriate text, and it’s trained on a large dataset to achieve this goal.
Read also - What is ChatGPT ? | step by step all explain .
Introduction Of ChatGPT
As an clever speak system, ChatGPT has exploded in popularity over the previous few days, producing a variety of buzz in the tech community and inspiring many to share ChatGPT-associated content and check examples on-line. The outcomes are superb. The remaining time I remember an AI technology causing the sort of sensation became whilst GPT-three become launched inside the field of NLP, which was over and a half years ago. Back then, the heyday of artificial intelligence become in full swing, but today it appears like a far off reminiscence. In the multimodal area, fashions like DaLL E2 and Stable Diffusion represented the Diffusion Model, which has been famous inside the final half 12 months with AIGC fashions. Today, the torch of AI has been handed to ChatGPT, which absolutely belongs to the AIGC category. So, within the cutting-edge low length of AI after the bubble burst, AIGC is indeed a lifesaver for AI. Of course, we stay up for the quickly-to-be-launched GPT-4 and hope that OpenAI can preserve to help the industry and convey a touch warmth.
Let’s not live on examples of ChatGPT’s talents, as they’re everywhere online. Instead, allow’s speak approximately the era behind ChatGPT and the way it achieves such awesome outcomes. Since ChatGPT is so powerful, can it replace present search engines like google and yahoo like Google? If so, why? If no longer, why no longer?
In this newsletter, I will attempt to solution these questions from my very own information. Please observe that some of my opinions can be biased and should be taken with a grain of salt. Let’s first have a look at what ChatGPT has completed to obtain such properly outcomes.
The Technical Principles of ChatGPT
In terms of ordinary era, ChatGPT builds upon the powerful GPT-three.5 large language model (LLM) and introduces “human-annotated statistics + reinforcement gaining knowledge of” (RLHF) to constantly high-quality-music the pre-skilled language model. The essential intention is to enable the LLM to recognize the which means of human commands (along with writing a short composition, generating solutions to knowledge questions, brainstorming one-of-a-kind types of questions, etc.) and to decide which solutions are excessive pleasant for a given set off (person question) based totally on multiple criteria (such as being informative, rich in content, useful to the consumer, harmless, and free of discriminatory records).
Read also - What is ChatGPT ? | step by step all explain .
Under the “human-annotated records + reinforcement gaining knowledge of” framework, the schooling technique of ChatGPT may be divided into the following three ranges:
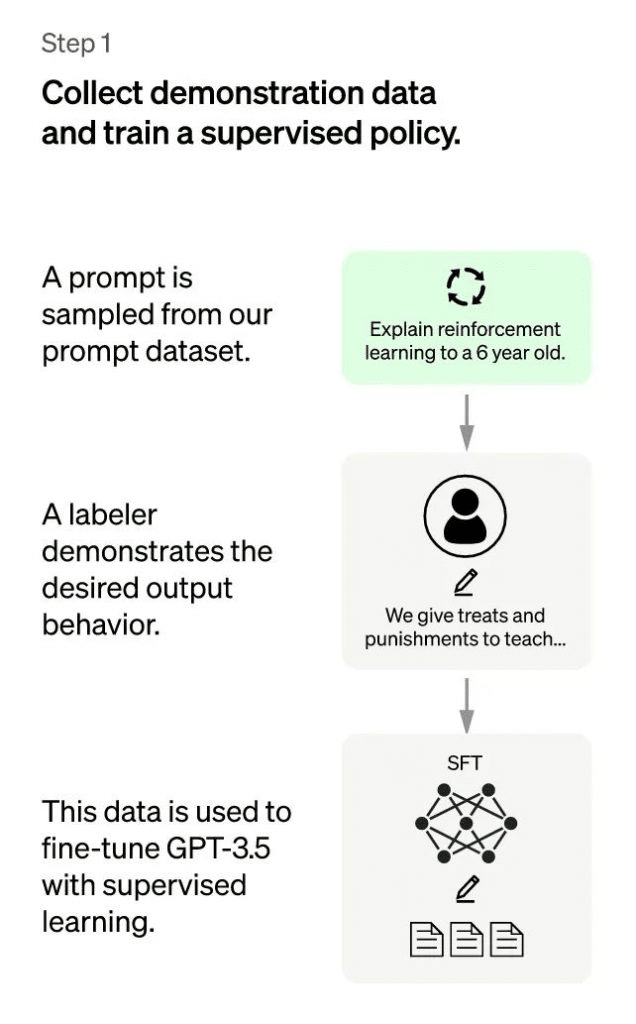
ChatGPT: First Stage
The first stage is a supervised coverage model throughout the bloodless start section. Although GPT-three.5 is robust, it’s miles tough for it to apprehend the unique intentions behind unique types of human instructions and to decide whether the generated content material is of excessive best. In order to give GPT-three.5 a initial expertise of the intentions in the back of commands, a batch of activates (i.E. Instructions or questions) submitted with the aid of check users might be randomly selected and professionally annotated to offer great solutions for the desired prompts. These manually annotated facts will then be used to pleasant-music the GPT-3.Five model. Through this method, we will do not forget that GPT-three.Five has to start with obtained the potential to understand the intentions contained in human activates and to offer fantastically awesome solutions based totally on those intentions. However, it’s miles obvious that this is not sufficient.
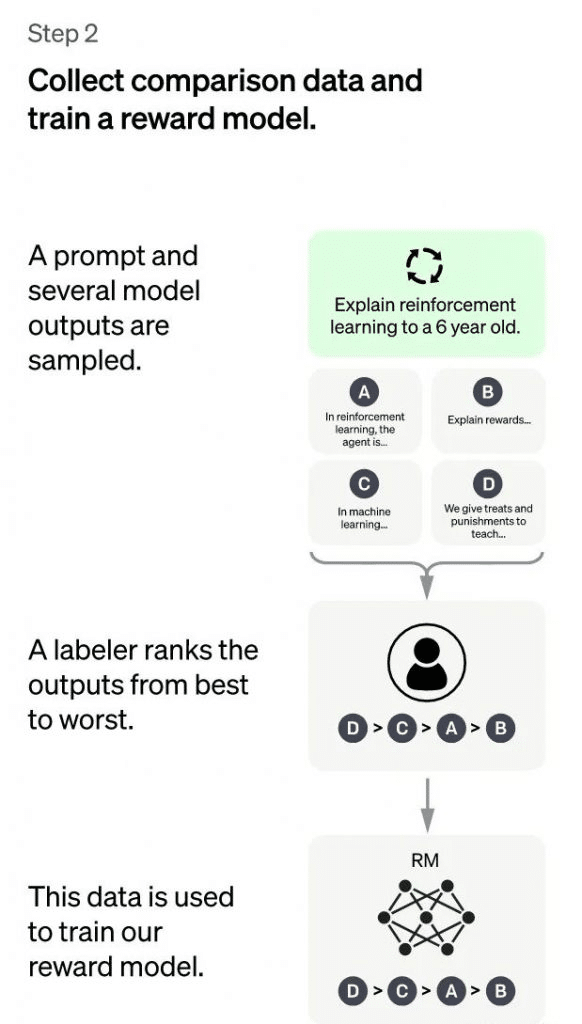
ChatGPT: Second Stage
The principal goal of the second one degree is to educate a reward model (RM) using manually annotated schooling records. This degree involves randomly sampling a batch of person-submitted prompts (which can be commonly the same as those within the first level), the usage of the bloodless-start version high-quality-tuned inside the first level to generate K different solutions for every prompt. As a result, the version produces the information ,,….. Then, the annotator kinds the K consequences consistent with multiple criteria (which includes relevance, informativeness, harmfulness, and so on.) and offers the ranking order of the K effects, which is the manually annotated records for this stage.
Next, we’re going to use the taken care of information to teach a praise model using the not unusual pair-wise studying to rank approach. For K looked after effects, we combine them with the aid of two to shape $binomk2$ training facts pairs. ChatGPT makes use of a pair-smart loss to educate the Reward Model. The RM version accepts an enter of and outputs a score that evaluates the excellent of the answer. For a schooling information pair , we anticipate that answer1 comes earlier than answer2 within the manual sorting, so the loss function encourages the RM version to attain higher than .
Read also - What is ChatGPT ? | step by step all explain .
In summary, on this segment, the supervised policy model generates K effects for every prompt after bloodless begin. The effects are manually looked after in descending order of fine, and used as training records to educate the praise version the use of the pair-wise getting to know to rank approach. For the educated RM model, the enter is , and the output is the excellent rating of the end result. The higher the rating, the better the high-quality of the generated reaction.
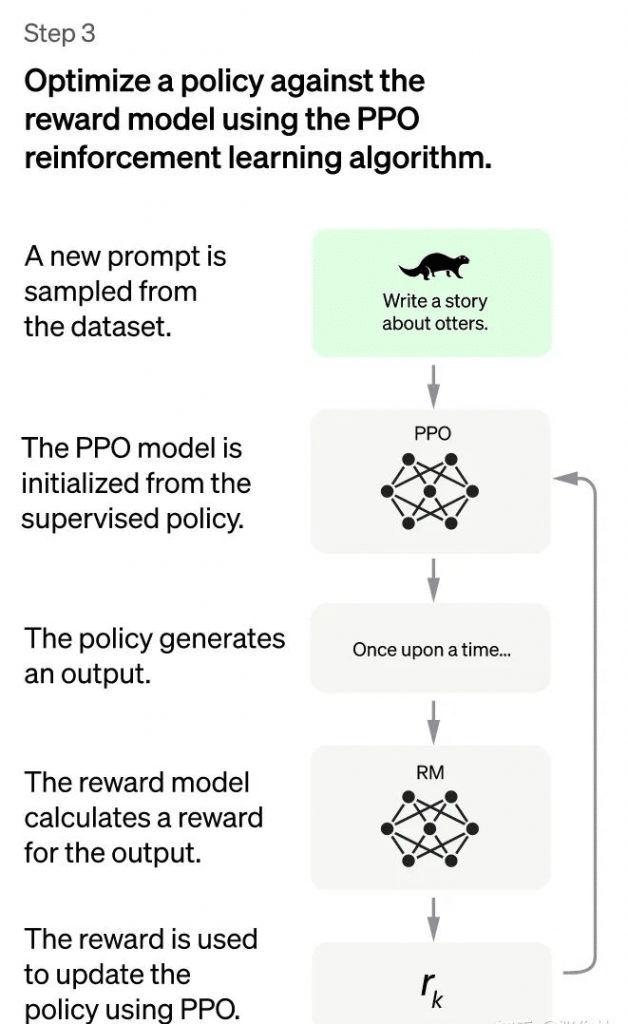
ChatGPT: Third Stage
In the 0.33 segment of ChatGPT, reinforcement gaining knowledge of is used to enhance the capability of the pre-skilled model. In this segment, no guide annotation statistics is wanted, however the RM model educated within the preceding section is used to update the parameters of the pre-educated model primarily based at the RM scoring consequences. Specifically, a batch of latest commands is randomly sampled from the consumer-submitted activates (that are distinct from the ones in the first and 2nd levels), and the parameters of the PPO model are initialized by means of the cold start version. Then, for the randomly decided on prompts, the PPO version generates solutions, and the RM model trained in the previous section presents a praise rating for the quality evaluation of the solutions. This praise score is the overall reward given with the aid of the RM to the complete solution (consisting of a series of phrases). With the very last reward of the series of phrases, each phrase can be appeared as a time step, and the reward is transmitted from back to the front, producing a policy gradient that can replace the PPO model parameters. This is the same old reinforcement getting to know technique, which ambitions to teach the LLM to produce excessive-praise solutions that meet the RM standards, that is, fantastic responses.
If we maintain to copy the second one and third levels, it’s miles apparent that every new release will make the LLM model increasingly more succesful. Because the second phase enhances the potential of the RM version via guide annotated facts, and within the 1/3 section, the enhanced RM version will rating the solutions to the brand new prompts extra accurately, and use reinforcement gaining knowledge of to inspire the LLM version to examine new extremely good content, which plays a function similar to using pseudo-labels to make bigger super education facts, so the LLM version is further better. Obviously, the second one segment and the third segment have a mutual promotion effect, that’s why non-stop iteration can have a sustained enhancement effect.
Despite this, I don’t suppose that the usage of reinforcement studying in the 0.33 phase is the primary cause why the ChatGPT model performs particularly nicely. Suppose that in the 1/3 segment, reinforcement gaining knowledge of is not used, but the following technique is used as a substitute: just like the second phase, for a new prompt, the bloodless begin version can generate okay answers, that are scored by using the RM model respectively, and we choose the answer with the highest rating to shape a brand new education facts to excellent-song the LLM model. Assuming that this mode is used, I agree with that its effect can be comparable to reinforcement learning, although it isn’t as sophisticated, but the effect won’t always be a good deal worse. No be counted what technical mode is adopted in the 1/3 section, it is basically possibly to use the RM found out inside the 2nd section to make bigger the splendid training statistics of the LLM model.
The above is the training process of ChatGPT, which is especially based at the paper of instructGPT. ChatGPT is an improved instructGPT, and the development factors are in particular exclusive in the method of accumulating annotated statistics. In different components, such as the version shape and education technique, it basically follows instructGPT. It is foreseeable that this Reinforcement Learning from Human Feedback generation will quick unfold to different content material generation instructions, along with a very clean to consider, much like “A system translation model primarily based on Reinforcement Learning from Human Feedback” and plenty of others. However, individually, I think that adopting this era in a particular content material technology area of NLP won’t be very meaningful anymore, due to the fact ChatGPT itself can handle a extensive variety of obligations, overlaying many subfields of NLP era, so if a subfield of NLP adopts this generation once more, it absolutely does now not have lots fee, because its feasibility is taken into consideration to were established through ChatGPT. If this era is implemented to other modal generation fields inclusive of images, audio, and video, it can be a greater worth direction to explore, and perhaps quickly we will see comparable work inclusive of “A XXX diffusion model based totally on Reinforcement Learning from Human Feedback”, which ought to nonetheless be very meaningful.
The 1/3 phase of the ChatGPT training procedure is to apply reinforcement gaining knowledge of to beautify the potential of the pre-skilled version. In this section, no human-labeled information is required, however instead the RM version educated in the preceding segment is used to replace the pre-educated model parameters primarily based on its scoring outcomes. Specifically, a batch of new commands (i.E. Activates which are specific from those utilized in levels 1 and a pair of) is randomly sampled from the person-submitted prompts, and the bloodless start model is used to initialize the PPO model parameters. Then, for the randomly sampled activates, the PPO version is used to generate solutions, and the RM version skilled inside the previous segment is used to provide a praise rating for the pleasant of the solutions. This reward score is the general reward given to the whole answer (along with a series of words) via the RM version. With the final reward of the phrase collection, each word may be considered as a time step, and the reward is exceeded returned from the stop to the start, generating a coverage gradient that can update the PPO version parameters. This is a trendy reinforcement learning technique, with the goal of schooling the LLM to provide high-reward answers, i.E. Exceptional answers that meet the RM requirements.
ChatGPT Can Replace Traditional Search Engines Like Google
Given that it looks like ChatGPT can almost answer any kind of prompt, it’s herbal to marvel: Can ChatGPT or a future model like GPT4 update conventional search engines like google and yahoo like Google? I in my opinion suppose that it’s no longer viable in the intervening time, but with a few technical changes, it is probably viable in theory to update traditional serps.
There are three principal reasons why the modern-day shape of chatGPT can’t update serps: First, for lots styles of expertise-related questions, chatGPT will provide answers that appear like reasonable however are surely incorrect. ChatGPT’s solutions seem well notion out and those like me, who are not nicely-knowledgeable, would trust them without problems. However, thinking about that it may solution many questions properly, this will be puzzling for users: if I don’t know the correct solution to the query I requested, should I accept as true with the result of ChatGPT or now not? At this factor, you cannot make a judgment. This trouble may be deadly.
Secondly, the contemporary model of ChatGPT, that is primarily based on a large GPT version and similarly educated with annotated statistics, is not friendly to the absorption of recent understanding by way of LLM fashions. New understanding is constantly emerging, and it’s miles unrealistic to re-educate the GPT version whenever a new piece of knowledge seems, whether in terms of schooling time or fee. If we adopt a Fine-tune mode for brand spanking new information, it seems feasible and relatively low-price, however it is simple to introduce new information and purpose disaster forgetting of the unique information, mainly for brief-term common fine-tuning, with the intention to make this hassle extra critical. Therefore, how to almost actual-timely integrate new expertise into LLM is a totally tough trouble.
Thirdly, the education fee and online inference cost of ChatGPT or GPT4 are too excessive, resulting in if going through actual seek engine’s tens of millions of user requests, assuming the continuation of the unfastened method, OpenAI can’t bear it, but if the charging method is adopted, it will significantly reduce the user base, whether or not to charge is a dilemma, of route, if the education fee can be greatly reduced, then the quandary may be self-solved. The above 3 motives have caused ChatGPT no longer being capable of update traditional engines like google at present.
Can these troubles be solved? Actually, if we take the technical path of ChatGPT as the main framework and absorb some of the prevailing technical way utilized by other speak structures, we will regulate ChatGPT from a technical perspective. Except for the price difficulty, the primary two technical problems noted above can be solved well. We just want to introduce the following talents of the sparrow machine into the ChatGPT: evidence show of the generated effects primarily based on the retrieval outcomes, and the adoption of the retrieval mode for brand new knowledge introduced by using the LaMDA system. Then, the well timed advent of new information and the credibility verification of generated content aren’t main troubles.
ChatGPT FAQ
-
What is the main architecture of ChatGPT?
ChatGPT is based on the transformer architecture, which consists of a multi-layer transformer encoder and a decoder. The encoder uses self-attention and feed-forward neural networks to process the input text, and the decoder generates the output text one word at a time, using the information from the encoder and an attention mechanism.
-
How does the self-attention mechanism work in ChatGPT?
The self-attention mechanism in ChatGPT allows the model to weigh the importance of each word in the input text when generating the output. It calculates the similarity between each word in the input and the current word being generated in the output, and uses this similarity to determine the importance of each word in the input for the current output word.
-
How is ChatGPT trained?
ChatGPT is trained on a large corpus of text data. It uses a deep neural network with a transformer architecture and fine-tuned on conversational data, to make it more proficient in generating responses in a conversational context.
-
What are the main advantages of the ChatGPT architecture?
The transformer architecture in ChatGPT allows the model to efficiently process large amounts of input text, and the self-attention mechanism enables it to generate highly coherent and contextually appropriate text. Additionally, fine-tuning it on conversational data makes it more proficient in generating responses in a conversational context.
-
How does ChatGPT improve over the basic GPT model?
ChatGPT is fine-tuned on conversational data to make it more proficient in generating responses in a conversational context. This fine-tuning process allows ChatGPT to improve its ability to understand and respond to conversational prompts in a more human-like manner than the basic GPT model.